Aufgabe 4: Alle reden vom Web 2.0 - Web 3.0 weiß das schon...
Lisa.Reinthaler.Uni-Sbg, 6. Juli 2010, 23:20
Lange Zeit galten Ausdrücke wie „Web2.0“, „Social Networking“, „Blogging“ & Co. als die technisierte, komplizierte, abgehobene Sprache der Nerd-Community - mittlerweile haben Marketingexperten, Webmaster und Internet-User die Begriffe mit Leben gefüllt und sie in unser aller Alltagsleben integriert. Das Internet bestimmt weite Bereiche unseres täglichen Lebens. Täglich werden wir mit dem Web 2.0 konfrontiert und haben uns so auch schrittweise mit seinen Ausprägungen und Möglichkeiten vertraut gemacht. Doch der Fortschritt schläft nicht, und schon gar nicht im Netz...
So ist seit geraumer Zeit schon wieder vom nächsten Quantensprung, dem künftigen Web 3.0 die Rede. Gleichzeitig tauchen Begriffe wie “semantisch”, “personalisiert” oder „clouding“ auf - wohlklingend und doch schwer definierbar. Das Web 3.0 oder Semantic Web soll ermöglichen, dass auch Maschinen die im Internet verfügbaren Informationen interpretieren und verarbeiten können und so zu einem „intelligenten Netz“ beitragen.
WEB 1.0
Das so genannte Web 1.0, dessen Bestehen dem britischen Informatiker Tim Berners-Lee zu verdanken ist, orientierte sich an der Funktionsweise der klassischen Massenmedien und daher auch der Einweg-Kommunikation. Die Nutzer waren von den übrigen Teilnehmern abgekapselt und galten als anonyme Masse, die lediglich lesen, kaufen und Werbebanneanklicken sollten. Der zentrale Aspekt war zu diesem Zeitpunkt die strikteTrennung zwischen Produzent und Konsument der angebotenen Informationen.
WEB 2.0
Mit dem Aufkommen von Web 2.0 entstand eine neue Generation von Aktivitäten und Diensten. Web 2.0 bietet dem Nutzer die Möglichkeit, Inhalte aktiv mitzugestalten. Er ist zugleich Konsument sowie Produzent von Inhalten, sogenannter „Prosumer“ (vgl. Sack 2006, S 6-9).
“Web 2.0 is the business revolution in the computer industry caused by the move to the Internet as a platform, and an attempt to understand the rules for success on that new platform.” (O’Reilly 2006)
Mittlerweile macht es das ständig wachsende Datenaufkommen im Web 2.0 immer schwieriger, relevante Informationen zu finden, darauf zuzugreifen und diese sinnvoll wiederzuverwerten, ob nun als Privatperson oder als Unternehmen.
Das nützlichste Werkzeug beim Suchen und Verwenden von Informationen sind zurzeit Suchmaschinen. Die auf Schlagwörtern basierenden Anbieter wie z.B. Google, yahoo etc. sind allerdings mit einigen Problemen verbunden: Sie liefern eine hohe Trefferzahl, leider aber auch oft geringe Genauigkeit, denn zu viele Suchergebnisse sind letztendlich genauso unbrauchbar wie zu wenige.
Außerdem können Wortdoppelbedeutungen nicht unterschieden werden und die Ergebnisse sind stets nur auf einzelnen Webseiten zu finden. Benötigen wir Informationen, die sich über mehrere Webseiten verteilen, müssen wir die Informationen selbst einzeln entnehmen und zusammenfügen.
Zwar gibt bereits Software, die Text verarbeiten, Rechtschreibung prüfen oder die Wörter zählen kann. Geht es aber darum, die Bedeutung von Sätzen zu interpretieren und daraus brauchbare Informationen für den Nutzer zu extrahieren, so sind alle verfügbaren Programme stark limitiert, wenn nicht gar unbrauchbar. Hierbei sind zwei Lösungsmöglichkeiten denkbar:
- Eine Lösungsmöglichkeit wäre, die Inhalte so zu belassen, wie sie heute sind
und die Maschinen mittels künstlicher Intelligenz und Computerlinguistik zu
verbessern. Die Wissenschaft verfolgt diesen Ansatz schon einige Zeit, allerdings wurde bis auf einige kleine Verbesserungen kein wesentlicher Durchbruch erreicht. - Ein anderer Ansatz ist, die Inhalte des World Wide Web so darzustellen, dass
sie leichter von Maschinen interpretiert und verarbeitet werden können.
Genau diese Vision entwarf der Erfinder des Internets, Tim Berners-Lee, ursprünglich mit seinem Hypertext-System. Der Entwurf für das World Wide Web (WWW) enthielt drei Kernpunkte: Zum einen entwickelte Berners-Lee die "Hypertext Markup Language" (HTML), die beschreibt, wie Seiten mit Hypertextverknüpfungen ("Links") auf unterschiedlichsten Rechnerplattformen formatiert werden. Mit dem "Hypertext Transfer Protocol" (HTTP) definierte er die Sprache, die Computer benützen würden, um über das Internet zu kommunizieren. Außerdem legte er mit dem "Universal Resource Identifier" (URI) das Schema fest, nach dem Dokumentenadressen erstellt und aufgefunden werden können. Seine Vision verfolgte zwei Ziele: Zum einen das Internet zu einem hochkollaborativen Medium zu machen und zum anderen es verständlicher zu machen, um so selbst Maschinen das Interpretieren und Verarbeiten der Inhalte zu ermöglichen.
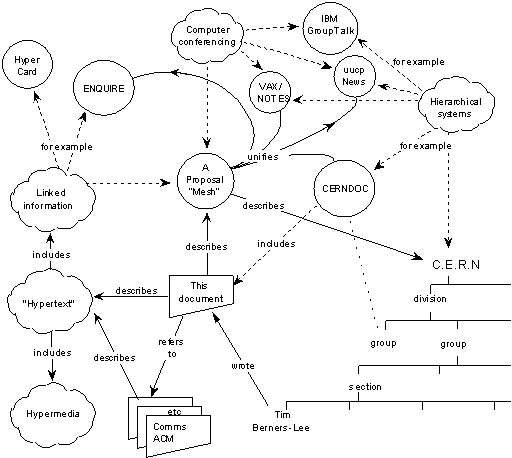
Das Diagramm zeigt, dass Berners-Lee ursprüngliche Vision mehr beinhaltete
als das bloße Abrufen von HTML-Dokumenten von Webservern. Die Abbildung stellt auch Relationen wie etwa “includes”, “wrote” und “describes” zwischen den einzelnen Informationselementen dar. Diese Relationen – auch als Metadaten zu bezeichnen – sind der Schlüssel, damit Maschinen die im Internet verfügbaren Informationen interpretieren und verarbeiten können. In den letzten Jahren treten nun immer mehr Entwicklungen auf, die in genau diese Richtung gehen.
Berners-Lee definiert das Semantic Web folgendermaßen:
„The Semantic Web is not a separate Web but an extension of the current one, in
which information is given well-defined meaning, better enabling computers and
people to work in cooperation” (Berners-Lee 2001, S. 10, zitiert nach Werres 2009,
S. 8)
Das World Wide Web Konsortium (W3C), das Gremium zur Standardisierung des World Wide Web unter dem Vorsitz von Tim Berners-Lee, legt folgende Ziele des Semantic Web fest:
- Wissensteilung und –austausch: Intelligente Software-Agenten verhelfen im
Semantic Web zu einer besseren Wissensteilung und einem besseren
Wissensaustausch. - Datenintegration: Es sind Daten vorhanden, die man jeden Tag nutzt und die
in Büchern, Blogs, Wikis, Kalendern, Fotos und PDF-Dokumenten vorhanden
sind. Einige dieser Daten werden von verschiedenen Applikationen genutzt.
Ein zentrales Ziel des Semantic Web ist, Daten mit verschiedenen Formaten
und aus diversen Orten in eine Applikation zu integrieren.
Beispielsweise könnte man in einem Online-Kalender Fotos ansehen und genau wissen, was man an diesem Tag machte, als man diese aufnahm, und auch, wie viel Geld man damals auf dem Konto hatte. - Quellen entdecken und klassifizieren: Durch semantische Technologien
können Informationen im Internet besser gefunden und klassifiziert werden.
Dadurch werden die Ergebnisse einer Suchmaschine optimiert und besser an
die individuellen Anforderungen der Benutzer angepasst.
Das klingt einerseits faszinierend, da einem aus dem riesigen Informationsangebot bereits vorsortierte Häppchen angeboten werden, die auf persönliche Interessen zugeschnitten sind. Andererseits wird einem auch wieder einmal bewusst, wie gläsern man geworden ist – und das ohne die aktive Bereitstellung der Informationen bzw. der Zustimmung zu deren Nutzung. Und genau das wird die Herausforderung dieser neuen Technologien sein: Datenschutz und Wahrung persönlicher Rechte und Privatsphäre.
Das Internet ist für viele Nutzer wie ein zweites Zuhause geowrden. Dort trifft man Freunde, Bekannte, man knüpft Kontakte, sucht die große Liebe und man teilt sich der Welt über Blogs und Netzwerke mit. Daten werden gesammelt und preisgegeben und über soziale Netzwerke und Webportale ausgetauscht.
Eine erste Gegenbewegung zu diesem oft unbedachten Umgang und in der Folge dem Handel mit Daten stellt das Projekt Diaspora dar. Gedacht als Konkurrenz zu Facebook und Co., geht das Soziale Netzwerk vier New Yorker Studenten in punkto Datenschutz und Privatsphäre neue Wege: Anstatt möglichst viele Daten über die Mitglieder zu sammeln, um diese kommerziell zu verwerten, wollen sie ein dezentrales Soziales Netzwerk starten, bei dem jeder Nutzer die Kontrolle über seine Daten behält. Das Open Source Social Network funktioniert ähnlich wie ein Peer-2-Peer Netzwerk für Filesharing, bei dem es ebenfalls keine zentralen Server mehr gibt. Im September soll Diaspora an den Start gehen.
Bleibt abzuwarten, ob der User 3.0 bereit ist, sich auf derartige neue Netzwerke zum Schutz seiner Privatshpäre einzulassen, oder er es doch eher mit Mark Zuckerberg hält. Der Facebook-Gründer bezeichnete Privatsphäre in einem Interview ja bekanntermaßen als „alte Konvention“ und „unzeitgemäß“.
Da schläft man als "Facebookianer" doch gleich wieder etwas ruhiger...
Quellen:
Berners-Lee, Tim (1998) „Semantic Web Road Map”. In W3C Design Issues.
http://www.w3.org/DesignIssues, abgerufen am 27.06.2010.
Blumauer, Andreas; Pellegrini, Tassilo (2006): „Semantic Web und semantische
Technologien: Zentrale Begriffe und Unterscheidungen“. In Blumauer,
Andreas; Pellegrini, Tassilo: „Semantic Web, Wege zur vernetzen Wissensgesellschaft“.
Springer Verlag, Berlin Heidelberg, S. 9-25.
http://www.werbeagentur.de/blog/allgemein/teil-6-ausblick-und-tendenzen-web-3-0/2010/05/31/
http://radar.oreilly.com/archives/2007/10/todays-web-30-nonsense-blogsto.html
http://www.trendone.de/home.html
Hallo!
eva-maria.poeltl.uni-linz, 7. Juli 2010, 10:41
Ein sehr ausführlicher Beitrag. Ich habe mich mit dem Thema Datenschutz vs. Vorratsdatenspeicherung beschäftigt. HIER zu meinem Beitrag!
LG, Eva.
Hallo Lisa,
christoph.priewasser.uni-linz, 7. Juli 2010, 20:04
Sehr interessanter Beitrag!! Ich habe mich mit dem Thema Privatsphäre und Facebook beschäftigt. Würde mich über ein Comment freuen...
Liebe Grüße aus Linz
Christoph
Die Arbeit Tim Berners Lee..
Hans.Mittendorfer.Uni-Linz, 27. Juli 2010, 11:50
.. möchte ich nicht schmälern, aber weder das Internet, noch den Hypertext möchte ich seinem Erfindergeist untersellen.
Darüber hinaus haben Sie sich um Ihre Ausarbeitung bemüht.