Mittwoch, 26. November 2003
RSS
nora.heindl.sbg, 11:31h
Was RSS ungefähr ist, wissen wir alle seit der letzten Vorlesung am 17. Nov. 2003, doch ich möchte das Thema hier noch einmal etwas genauer behandeln:
Was heißt RSS?
Es gibt für diese Abkürzung einige Bedeutungen, wie „Really Simple Syndication“, „Rich Site Summary“ oder „RDF Site Summary“, dies hängt mit der Entstehungsgeschichte der verschiedenen RSS-Versionen zusammen.
Nutzen von RSS?
Ich bin im Internet zufällig auf eine sehr einfach zu verstehende Erklärung von RSS gestoßen. Es geht darum, dass es anstatt selbst zum Bäcker zu gehen, die Brötchen auszusuchen und danach wieder ins Büro zu gehen, es viel schöner wäre, wenn der Bäcker mit seinen Brötchen ins Büro kommt, man sich die Brötchen bequem aus dem Bürostuhl heraus aussuchen kann und trotzdem den gleichen Preis bezahlt. Genau das versteht man unter RSS. Man spart Zeit, es kostet nicht mehr und man hat die gleiche Auswahl wie vorher.
Viele Besucher suchen meist oft täglich viele verschiedene Webseiten auf, doch es kostet Zeit, die immer größer werdende Anzahl von abzusurfenden Seiten im Überblick zu halten.
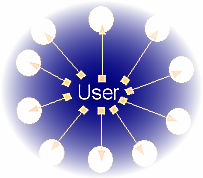
Es kommt auch immer wieder vor, dass der User einige der Seiten ganz umsonst aufsucht, da es keine neuen Informationen gibt, was einen großen Zeitverlust mit sich bringt. Hier kommt der Einsatz von RSS. Dem User werden ganz von selbst nur die neuen und für ihn interessanten Beiträge „gebracht“. Was für den User interessante Informationen (zB Artikel von oder mit einer bestimmten Person, mit einem besonderen Begriff, ...) sind, klärt man schon bei der Abonnierung eines RSS-Feed (= das Futter, um Infos von den Seiten geliefert zu bekommen).
Funktion?
Oft findet man auf einer Seite dieses Symbol: oder auch einen dieser folgenden Links: „RSS“, „RDF“, „Channel“ oder „XML“. Zu diesen genannten RSS-Dateien gibt es natürlich auch verschiedene Versionen, zB „0.91“, „0.92“, „0.93“, „0.94“, „1.0“, „2.0“, etc., die beiden häufigsten sind „0.91“ und „0.92“. Beinahe jeder RSS-Reader kann sie lesen.
oder auch einen dieser folgenden Links: „RSS“, „RDF“, „Channel“ oder „XML“. Zu diesen genannten RSS-Dateien gibt es natürlich auch verschiedene Versionen, zB „0.91“, „0.92“, „0.93“, „0.94“, „1.0“, „2.0“, etc., die beiden häufigsten sind „0.91“ und „0.92“. Beinahe jeder RSS-Reader kann sie lesen.
Hat man also so eine RSS-Datei gefunden, braucht man die URL dieser Datei. Diese wird dann einfach unter Windows kopiert (rechte Maustaste auf Link/Symbol und „Verknüpfung kopieren“ oder „Link kopieren“ wählen). Jetzt geht man zu seinem ausgewählten RSS-Reader, wählt dort „add new channel“ oder „new feed“ und fügt mit der Tastenkombination Strg + V die zuvor kopierte URL in das dafür vorgesehene Feld. Die genau Anleitung, wie man dann einen RSS-Feed einfügt, erklärt jeder RSS-Reader selbst. Für alle die es gleich wissen wollen, man kopiert einfach den auf der Webseite gefundenen Link wie ein Bookmark in die Seite des RSS-Reader. Das wars!
Und schon erspart man sich jede Menge Zeit und sogar Kosten bei nicht-pauschal abgerechneten Internetverbindungen, da insgesamt weniger Daten übertragen und nach der Aktualisierung der RSS-Feeds die meisten Meldungen auch offline gelesen werden können.
Woher bekomme ich so einen RSS-Reader?
SharpReader (Windows + Microsoft.Net Framework runtime version 1.0)
Awasu (Windows)
Feedreader (Windows)
NetNewsWire (Mac)
Für RSS-Einsteiger ist der Feedreader der am geeignetsten.
Wo finde ich RSS-Feeds?
auf jeder Seite mit den oben genannten RSS-Dateien
im deutschsprachigen RSS-Verzeichnis von bloghaus.net
im englischen bei Radio Community Server oder syndic8.com
Um noch mehr über RSS zu erfahren, möchte ich auf die Weblogs von Christian Koeppe und Stephan Ziep, beide aus Berlin, verweisen. Dort findet ihr noch weitere Tipps für den Umgang mit RSS.
Was heißt RSS?
Es gibt für diese Abkürzung einige Bedeutungen, wie „Really Simple Syndication“, „Rich Site Summary“ oder „RDF Site Summary“, dies hängt mit der Entstehungsgeschichte der verschiedenen RSS-Versionen zusammen.
Nutzen von RSS?
Ich bin im Internet zufällig auf eine sehr einfach zu verstehende Erklärung von RSS gestoßen. Es geht darum, dass es anstatt selbst zum Bäcker zu gehen, die Brötchen auszusuchen und danach wieder ins Büro zu gehen, es viel schöner wäre, wenn der Bäcker mit seinen Brötchen ins Büro kommt, man sich die Brötchen bequem aus dem Bürostuhl heraus aussuchen kann und trotzdem den gleichen Preis bezahlt. Genau das versteht man unter RSS. Man spart Zeit, es kostet nicht mehr und man hat die gleiche Auswahl wie vorher.
Viele Besucher suchen meist oft täglich viele verschiedene Webseiten auf, doch es kostet Zeit, die immer größer werdende Anzahl von abzusurfenden Seiten im Überblick zu halten.
Es kommt auch immer wieder vor, dass der User einige der Seiten ganz umsonst aufsucht, da es keine neuen Informationen gibt, was einen großen Zeitverlust mit sich bringt. Hier kommt der Einsatz von RSS. Dem User werden ganz von selbst nur die neuen und für ihn interessanten Beiträge „gebracht“. Was für den User interessante Informationen (zB Artikel von oder mit einer bestimmten Person, mit einem besonderen Begriff, ...) sind, klärt man schon bei der Abonnierung eines RSS-Feed (= das Futter, um Infos von den Seiten geliefert zu bekommen).
Funktion?
Oft findet man auf einer Seite dieses Symbol:
Hat man also so eine RSS-Datei gefunden, braucht man die URL dieser Datei. Diese wird dann einfach unter Windows kopiert (rechte Maustaste auf Link/Symbol und „Verknüpfung kopieren“ oder „Link kopieren“ wählen). Jetzt geht man zu seinem ausgewählten RSS-Reader, wählt dort „add new channel“ oder „new feed“ und fügt mit der Tastenkombination Strg + V die zuvor kopierte URL in das dafür vorgesehene Feld. Die genau Anleitung, wie man dann einen RSS-Feed einfügt, erklärt jeder RSS-Reader selbst. Für alle die es gleich wissen wollen, man kopiert einfach den auf der Webseite gefundenen Link wie ein Bookmark in die Seite des RSS-Reader. Das wars!
Und schon erspart man sich jede Menge Zeit und sogar Kosten bei nicht-pauschal abgerechneten Internetverbindungen, da insgesamt weniger Daten übertragen und nach der Aktualisierung der RSS-Feeds die meisten Meldungen auch offline gelesen werden können.
Woher bekomme ich so einen RSS-Reader?
Für RSS-Einsteiger ist der Feedreader der am geeignetsten.
Wo finde ich RSS-Feeds?
Um noch mehr über RSS zu erfahren, möchte ich auf die Weblogs von Christian Koeppe und Stephan Ziep, beide aus Berlin, verweisen. Dort findet ihr noch weitere Tipps für den Umgang mit RSS.
... comment
christian_koeppe_berlin,
Mittwoch, 26. November 2003, 12:52
'Unsere' RSS-Feeds
Schöne Erklärung! Da ich mich mit den RSS-Feeds unseres Servers beschäftige, möchte ich an dieser Stelle auf die entsprechende Story verweisen:
/blogville/stories/606/
Es gibt bereits Feeds für den Server als solchen (mit den zuletzt aktualisierten Weblogs als Items), für einen Weblog (mit allen Stories als Items) sowie für eine Story (mit allen Kommentaren als Items). Diese sind jeweils über Hinzufügen von /rss im jeweiligen Kontext abrufbar (in obiger Story beschrieben).
Ich arbeite noch an weiteren Feeds und sammle dafür Vorschläge in der folgenden Story:
/blogville/stories/2247/
viele Grüße aus Berlin
Christian Köppe
/blogville/stories/606/
Es gibt bereits Feeds für den Server als solchen (mit den zuletzt aktualisierten Weblogs als Items), für einen Weblog (mit allen Stories als Items) sowie für eine Story (mit allen Kommentaren als Items). Diese sind jeweils über Hinzufügen von /rss im jeweiligen Kontext abrufbar (in obiger Story beschrieben).
Ich arbeite noch an weiteren Feeds und sammle dafür Vorschläge in der folgenden Story:
/blogville/stories/2247/
viele Grüße aus Berlin
Christian Köppe
... link
... comment
stephan_ziep_berlin,
Donnerstag, 27. November 2003, 00:02
RSS-Ticker
Hallo, ich habe gerade einen RSS-NewsTicker für Collabor geschrieben. Den kann man in seinem Blog anzeigen und RSS-Feeds zum tickern geben (siehe Christian oben). Vielleicht kannst Du den Ticker ja in Deine Liste aufnehmen? Weitere Infos hier
... link
... comment
Online for 7920 days
Last update: 2004.01.16, 16:53
Last update: 2004.01.16, 16:53
status
You're not logged in ... login
menu
search
calendar
November 2003 |
||||||
Mo |
Di |
Mi |
Do |
Fr |
Sa |
So |
1 |
2 |
|||||
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
22 |
||
24 |
25 |
27 |
29 |
30 |
||
recent updates
Suchmaschinen
"Die allgemeine Suchmaschine benötigt keine menschliche...
"Die allgemeine Suchmaschine benötigt keine menschliche...
by katrin_schoenherr_berlin (2004.01.16, 16:53)
!!!Umfrage!!!
Welcher Anbieter nun über die beste Suchmaschine...
Welcher Anbieter nun über die beste Suchmaschine...
by nora.heindl.sbg (2003.12.02, 19:03)
Und so geht`s!
Suchmaschinen versprechen uns einen schnellen Zugang...
Suchmaschinen versprechen uns einen schnellen Zugang...
by nora.heindl.sbg (2003.11.29, 09:39)
sonderzeichen
bei manchen suchmaschinen werden zeichen wie "+" und...
bei manchen suchmaschinen werden zeichen wie "+" und...
by stephan_ziep_berlin (2003.11.28, 17:10)