
Montag, 4. Februar 2008
Montag, 4. Februar 2008
Literaturverwaltung mittels virtuellem Bücherregal
Topic: 'Aufgaben (NiM)'
Neben zahlreichen Web 2.0-Diensten zählt auch die Literaturverwaltung mittels virtuellen Bücherregalen zu dieser Gruppe. Warum diese Art zu den Web 2.0-Diensten gezählt wird, was sie ausmacht usw. soll anhand von dem Beispiel Library Thing erklärt werden.
1. Library Thing
Library Thing kann man sich als ein virtuelles Bücherregal vorstellen. Hierbei geht es aber nicht um das Entleihen von Büchern wie es bei Bibliotheken getan werden kann. Generell verfügt diese Internetseite vor allem folgende zwei Funktionen:
1. Eine Art Bücherkatalog erstellen, in dem Bücher hineingestellt werden können, die man zurzeit liest, oder gelesen hat oder jene, die zu den eigenen Lieblingsbüchern gehört.
2. Stellt eine Verbindung zu anderen Personen her, die ebenfalls dasselbe Buch wie ich gelesen und in dieser Online-Bibliothek angegeben haben. (Quelle: Vgl. Library Thing)
Bei diesem Online-Tool können folgende Bereiche unterschieden werden:
1.1. Bücher suchen und finden
Um Bücher zu der eigenen Bibliothek hinzuzufügen, muss man lediglich einen Teil des Titels oder des Autors eingeben um dann das richtige Buch auswählen zu können. Hierfür werden „die richtigen Daten bei Amazon.de und über 252 Bibliotheken weltweit, einschließlich der Library of Congress,“ zusammengesucht. (Quelle: Vgl. Library Thing)
Bücher können spezifisch anhand der folgenden Tools gefunden werden: Werke (Titel/Autor/ISBN), Autoren oder Tags. Unter dem letztgenannten Begriff kann verstanden werden, dass die Anwender „die Bücher mit eigenen Schlagwörtern, den so genannten Tags versehen und ihre virtuelle Bibliothek so thematisch ordnen können“. (Quelle: Vgl. Bibliotheksystem Universität Hamburg)
Darüber hinaus können mit der Suchfunktion diverse Foren-Einträge, nach Gruppen, Mitgliedern, Wohnort usw. gefunden werden.
1.2. BookSuggester & UnSuggester
Mittels dieser beiden Begriffe ist es für den Anwender möglich, Bücher wiederrum nach dem Titel oder Autor zu finden, aber mit einem wesentlichen Unterschied zur „normalen Suche“. Und zwar können mit dem Booksuggester Bücher gefunden werden, die von anderen Benutzern empfohlen sowie mit dem Unsuggester jene, die nicht weiter empfohlen werden. Ein Beispiel ist in folgender Abbildung ersichtlich, die das Suchergebnis nach der Zahl „1984“ als Bestandteil des Titels von dem gleichnamigen Buch von George Orwell darstellen soll. (Quelle: Vgl. Library Thing)

1.3. Bücher sortieren und bewerten
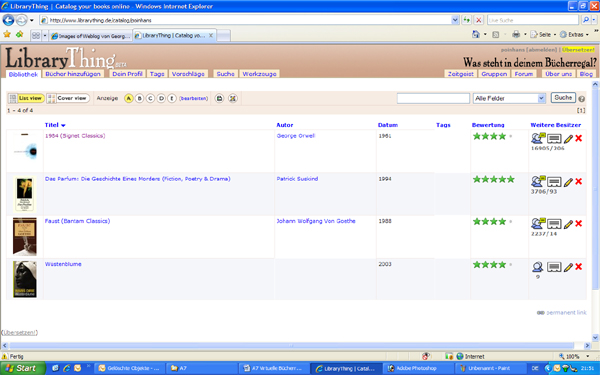
In der eigenen Bücherübersicht besteht die Möglichkeit die Bücher nach Titel oder Autor zu sortieren, eine Bewertung abzugeben und die Bücher mit Tags zu versehen. Die folgende Abbildung zeigt eine kleine Übersicht über einige Bücher sowie die soeben angesprochenen Funktionen. (Quelle: Vgl. Library Thing)
1.4. Interaktion untereinander
Weshalb diese virtuelle Bücherei zu den Web 2.0-Diensten gezählt wird, ist ganz einfach zu erklären. Und zwar hat diese als weiteres wesentliches Kriterium die Funktion der Interaktion mit anderen Buchlesern und -kennern. Weiters wird ermöglicht, aufzuzeigen, welche Meinung andere Benutzer zu den eigens ausgewählten Büchern haben. Darüber hinaus können Gruppen eingerichtet (öffentliche und/oder private zu bestimmten Buchclubs, Lokalitäten etc.) und auch Gruppen beigetreten werden. Darin geht es vor allem um die Kommunikation mit den Mitgliedern der jeweiligen Gruppe. Dadurch wird ermöglicht sich über bestimmte Bücher, Autoren und vielem mehr zu unterhalten. (Quelle: Vgl. Library Thing)
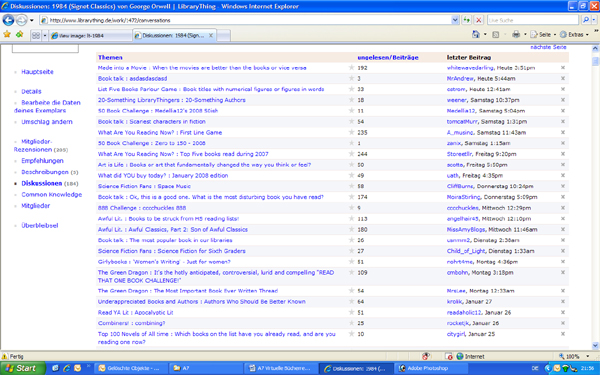
Folgende Abbildungen sollen die soeben angesprochenen Funktionen bildlich darstellen. Das erste Bild zeigt spezifische Angaben zu einem bestimmten Buch. In diesem Fall wird unter anderem gezeigt, dass 16.904 Mitglieder ebenfalls das Buch „1984 von George Orwell“ gelesen haben, dieses eine durchschnittliche Bewertung von 4,29 Sternen (von maximal 5 Sternen) erhalten hat sowie 184 Diskussionen geführt werden. In der zweiten Abbildung wird ein Auszug über die genannten Diskussionen gezeigt. (Quelle: Vgl. Library Thing)
2. Quellen:
Hier sind die im Beitrag verwendeten Quellen nochmals überblicksmäßig dargestellt:
- Bibliotheksystem Universität Hamburg
- Library Thing
1. Library Thing
Library Thing kann man sich als ein virtuelles Bücherregal vorstellen. Hierbei geht es aber nicht um das Entleihen von Büchern wie es bei Bibliotheken getan werden kann. Generell verfügt diese Internetseite vor allem folgende zwei Funktionen:
1. Eine Art Bücherkatalog erstellen, in dem Bücher hineingestellt werden können, die man zurzeit liest, oder gelesen hat oder jene, die zu den eigenen Lieblingsbüchern gehört.
2. Stellt eine Verbindung zu anderen Personen her, die ebenfalls dasselbe Buch wie ich gelesen und in dieser Online-Bibliothek angegeben haben. (Quelle: Vgl. Library Thing)
Bei diesem Online-Tool können folgende Bereiche unterschieden werden:
1.1. Bücher suchen und finden
Um Bücher zu der eigenen Bibliothek hinzuzufügen, muss man lediglich einen Teil des Titels oder des Autors eingeben um dann das richtige Buch auswählen zu können. Hierfür werden „die richtigen Daten bei Amazon.de und über 252 Bibliotheken weltweit, einschließlich der Library of Congress,“ zusammengesucht. (Quelle: Vgl. Library Thing)
Bücher können spezifisch anhand der folgenden Tools gefunden werden: Werke (Titel/Autor/ISBN), Autoren oder Tags. Unter dem letztgenannten Begriff kann verstanden werden, dass die Anwender „die Bücher mit eigenen Schlagwörtern, den so genannten Tags versehen und ihre virtuelle Bibliothek so thematisch ordnen können“. (Quelle: Vgl. Bibliotheksystem Universität Hamburg)
Darüber hinaus können mit der Suchfunktion diverse Foren-Einträge, nach Gruppen, Mitgliedern, Wohnort usw. gefunden werden.
1.2. BookSuggester & UnSuggester
Mittels dieser beiden Begriffe ist es für den Anwender möglich, Bücher wiederrum nach dem Titel oder Autor zu finden, aber mit einem wesentlichen Unterschied zur „normalen Suche“. Und zwar können mit dem Booksuggester Bücher gefunden werden, die von anderen Benutzern empfohlen sowie mit dem Unsuggester jene, die nicht weiter empfohlen werden. Ein Beispiel ist in folgender Abbildung ersichtlich, die das Suchergebnis nach der Zahl „1984“ als Bestandteil des Titels von dem gleichnamigen Buch von George Orwell darstellen soll. (Quelle: Vgl. Library Thing)
1.3. Bücher sortieren und bewerten
In der eigenen Bücherübersicht besteht die Möglichkeit die Bücher nach Titel oder Autor zu sortieren, eine Bewertung abzugeben und die Bücher mit Tags zu versehen. Die folgende Abbildung zeigt eine kleine Übersicht über einige Bücher sowie die soeben angesprochenen Funktionen. (Quelle: Vgl. Library Thing)
1.4. Interaktion untereinander
Weshalb diese virtuelle Bücherei zu den Web 2.0-Diensten gezählt wird, ist ganz einfach zu erklären. Und zwar hat diese als weiteres wesentliches Kriterium die Funktion der Interaktion mit anderen Buchlesern und -kennern. Weiters wird ermöglicht, aufzuzeigen, welche Meinung andere Benutzer zu den eigens ausgewählten Büchern haben. Darüber hinaus können Gruppen eingerichtet (öffentliche und/oder private zu bestimmten Buchclubs, Lokalitäten etc.) und auch Gruppen beigetreten werden. Darin geht es vor allem um die Kommunikation mit den Mitgliedern der jeweiligen Gruppe. Dadurch wird ermöglicht sich über bestimmte Bücher, Autoren und vielem mehr zu unterhalten. (Quelle: Vgl. Library Thing)
Folgende Abbildungen sollen die soeben angesprochenen Funktionen bildlich darstellen. Das erste Bild zeigt spezifische Angaben zu einem bestimmten Buch. In diesem Fall wird unter anderem gezeigt, dass 16.904 Mitglieder ebenfalls das Buch „1984 von George Orwell“ gelesen haben, dieses eine durchschnittliche Bewertung von 4,29 Sternen (von maximal 5 Sternen) erhalten hat sowie 184 Diskussionen geführt werden. In der zweiten Abbildung wird ein Auszug über die genannten Diskussionen gezeigt. (Quelle: Vgl. Library Thing)
2. Quellen:
Hier sind die im Beitrag verwendeten Quellen nochmals überblicksmäßig dargestellt:
- Bibliotheksystem Universität Hamburg
- Library Thing
Samstag, 26. J�nner 2008
Samstag, 26. J�nner 2008
Einsetzen von Netzwerktools
Topic: 'Aufgaben (NiM)'
In dieser Aufgabenstellung geht es, wie der Titel schon sagt, um das Einsetzen von Netzwerktools. In diesem Zusammenhang wird zuerst auf die Befehle ping & tracert, danach auf den Portscan und zu guter letzt auf eine< b>whois-Abfrage eingegangen.
1. ping & tracert
1.1. Definitionen
Der Begriff ping ist die Abkürzung für „Packet Internet Groper“. Dieser Befehl wird eingesetzt (z.B. in der Eingabeaufforderung) um zu testen wie Netzwerke oder generell Rechner im Internet erreichbar sind. Hierbei erfolgt mittels dem Befehl ping eine Zusendung eines Signals an den Rechner den man erreichen möchte und erhält folglich als Ergebnis die Dauer, wie lange es dauert, bis eine Antwort von diesem Rechner zurückkommt.
(Quelle: Vgl. Lexikon Suchmaschinenoptimierung)
Des Weiteren wird der Begriff ping laut Wikipedia wie folgt noch definiert: „ping ist ein Computerprogramm, mit dem überprüft werden kann, ob ein bestimmter Host in einem IP-Netzwerk erreichbar ist und welche Zeit das Routing von ihm weg und wieder zurück in Anspruch nimmt“.
(Quelle: Vgl. Wikipedia)
Der zweite Begriff, den es hier zu definieren gilt, ist tracert. Dieser Befehl, auch bekannt als traceroute (bei dem Betriebssystem Unix/Linux), fungiert ähnlich wie der zuvor definierte Begriff ping. Hierbei ist es möglich „noch mehr Informationen über die Netzwerkverbindung zwischen der lokalen Station und der entfernten Station“ zu bekommen. Wie der Name traceroute (übersetzt ins Deutsche) schon sagt, geht es hierbei um eine Routenverfolgung. Es wird z.B. verwendet, wenn man herausfinden möchte, ob „die Datenpakete auf dem Weg zum Ziel die richtige Route verwenden“. Ist dies nicht der Fall, d.h. die Datenpakete gelangen nicht zum Ziel, so kann mit tracert jene Station bzw. jenen Rechner ermitteln der zum Ausfall führte.
(Quelle: Vgl. das ELKO)
1.2. Test der Befehle & Interpretation
Die Befehle ping und tracert wurden an zwei unterschiedlichen Tagen an der Internetseite www.orf.at getestet, um die Funktion sowie die Unterschiede dieser Befehle aufzuzeigen.
ping
(Freitag, 25. Jänner 2007, 17:26 Uhr)
")
ping
(Samstag, 26. Jänner 2007, 17:26 Uhr)
")
Bei der Ausführung dieses Befehls war der Zielhost an beiden Tagen nicht erreichbar. Somit wurden keine Pakete gesendet und dadurch war es auch nicht möglich Zeitangaben zu erhalten. Der einzige Unterschied der bestand, ist, dass sich die IP-Adresse geändert hatte, nämlich von 194.232.104.26 auf 194.232.104.24.
tracert
(Freitag, 25. Jänner 2007, 17:30 Uhr)
")
tracert
(Samstag, 26. Jänner 2007, 17:32 Uhr)
")
Wie aus der Definition bereits bekannt ist, so geht es hier um eine Routenverfolgung. Wie man erkennen kann zeigt der Routenverlauf 9 Serverstationen bis dann bei der 10. Serverstation die Seite www.orf.at (= Zielserver) angezeigt wird. Ebenso wie beim Befehl ping, ändert sich auch hier die IP-Adresse von 194.232.104.26 auf 194.232.104.24. Des Weiteren ist ersichtlich, dass am Samstag, den 26. Jänner 2007, die ms (Mikrosekunde) teils größer ist als am Freitag, den 25. Jänner 2007.
2. Portscan
Mit diesem Tool kann festgestellt werden, welche Ports an einem Computer offen sind. D.h., dass dieser Rechner an ein Netzwerk oder an das Internet angeschlossen sein muss um einen Portscan durchführen zu können. Ein solcher Port gilt dann als offen, „wenn Anfragen an diesen Port von der entsprechenden Software bearbeitet werden“.
(Quelle: Vgl. lexexakt.de)
Zur Durchführung eines Portscans auf meinem Rechner, verwendete ich das Online-Portscan Tool von port-scan.de. Hierfür habe ich einen Schnelltest durchgeführt, der mir folgendes Bild als Ergebnis zeigte.
")
Wie man anhand des Gesamtstatus sehen kann, gilt mein Rechner bzw. meine Ports als sicher. D.h., dass keine der getesteten Ports offen ist bzw. diese durch eine Firewall oder einen Paketfilter überwacht werden.
3. whois-Abfrage
Der Abfragebefehl whois ist englisch und lautet ausgeschrieben „who is“ bzw. „wer ist“. Laut Wikipedia ist whois „ein Protokoll, mit dem von einem verteilten Datenbanksystem Informationen zu Internet-Domains und IP-Adressen und deren Eigentümern abgefragt werden können.
(Quelle: Vgl. Wikipedia)
Im Zusammenhang mit der auszuarbeitenden Aufgabenstellung wurde die whois-Abfrage an der Internetseite des ORF durchgeführt. Folgende Informationen konnten dadurch gewonnen werden:
domain: orf.at
registrant: OR853245-NICAT
admin-c: SL521785-NICAT
tech-c: JJ517250-NICAT
tech-c: ADA567013-NICAT
nserver: ns1.apa.at
remarks: 194.158.133.1
nserver: ns2.apa.at
remarks: 194.158.133.21
changed: 20010509 17:22:26
source: AT-DOM
personname: Stefan Lauterer
organization: Oesterreichischer Rundfunk
street address: Argentinierstrasse 31
postal code: A-1040
city: Wien
country: Austria
phone: +4318787818339
fax-no: +431503621580
e-mail: stefan.lauterer@orf.at
nic-hdl: OR853245-NICAT
changed: 20010509 17:22:24
source: AT-DOM
personname: Stefan Lauterer
organization:
street address: Oesterreichischer Rundfunk
street address: Argentinierstrasse 31
street address: A-1040 Wien
street address: Austria
postal code:
city:
country:
phone: +43 1 87878 18339
fax-no: +43 1 5036215 80
e-mail: stefan.lauterer@orf.at
nic-hdl: SL521785-NICAT
changed: 20001207 11:00:54
source: AT-DOM
personname: Josef Jezek
organization:
street address: ORF Oesterreichischer Rundfunk
street address: Wuerzburggasse 30
street address: A-1136
street address: Austria
postal code:
city:
country:
phone: +43 1 87878 14008
fax-no: +43 1 87878 14949
e-mail: josef.jezek@orf.at
nic-hdl: JJ517250-NICAT
changed: 20000825 13:21:19
source: AT-DOM
personname: APA DNS Admin
organization: APA Austria Presse Agentur
street address: Laimgrubengasse 10
postal code: A-1060
city: Wien
country: Austria
e-mail: domain-admin@apa.at
nic-hdl: ADA567013-NICAT
changed: 20051110 13:29:58
source: AT-DOM
Wie aus der Abfrage ersichtlich ist, so ist die Domain orf.at auf Stefan Lauterer registriert. Darüber hinaus lassen sich Daten ablesen wie Adresse, Telefonnummer etc.
4. Quellen:
Hier sind die im Beitrag verwendeten Quellen nochmals überblicksmäßig dargestellt:
- das ELKO
- lexexakt.de
- Lexikon Suchmaschinenoptimierung
- ORF
- port-scan.de
- Wikipedia: ping
- Wikipedia: whois
1. ping & tracert
1.1. Definitionen
Der Begriff ping ist die Abkürzung für „Packet Internet Groper“. Dieser Befehl wird eingesetzt (z.B. in der Eingabeaufforderung) um zu testen wie Netzwerke oder generell Rechner im Internet erreichbar sind. Hierbei erfolgt mittels dem Befehl ping eine Zusendung eines Signals an den Rechner den man erreichen möchte und erhält folglich als Ergebnis die Dauer, wie lange es dauert, bis eine Antwort von diesem Rechner zurückkommt.
(Quelle: Vgl. Lexikon Suchmaschinenoptimierung)
Des Weiteren wird der Begriff ping laut Wikipedia wie folgt noch definiert: „ping ist ein Computerprogramm, mit dem überprüft werden kann, ob ein bestimmter Host in einem IP-Netzwerk erreichbar ist und welche Zeit das Routing von ihm weg und wieder zurück in Anspruch nimmt“.
(Quelle: Vgl. Wikipedia)
Der zweite Begriff, den es hier zu definieren gilt, ist tracert. Dieser Befehl, auch bekannt als traceroute (bei dem Betriebssystem Unix/Linux), fungiert ähnlich wie der zuvor definierte Begriff ping. Hierbei ist es möglich „noch mehr Informationen über die Netzwerkverbindung zwischen der lokalen Station und der entfernten Station“ zu bekommen. Wie der Name traceroute (übersetzt ins Deutsche) schon sagt, geht es hierbei um eine Routenverfolgung. Es wird z.B. verwendet, wenn man herausfinden möchte, ob „die Datenpakete auf dem Weg zum Ziel die richtige Route verwenden“. Ist dies nicht der Fall, d.h. die Datenpakete gelangen nicht zum Ziel, so kann mit tracert jene Station bzw. jenen Rechner ermitteln der zum Ausfall führte.
(Quelle: Vgl. das ELKO)
1.2. Test der Befehle & Interpretation
Die Befehle ping und tracert wurden an zwei unterschiedlichen Tagen an der Internetseite www.orf.at getestet, um die Funktion sowie die Unterschiede dieser Befehle aufzuzeigen.
ping
(Freitag, 25. Jänner 2007, 17:26 Uhr)
ping
(Samstag, 26. Jänner 2007, 17:26 Uhr)
Bei der Ausführung dieses Befehls war der Zielhost an beiden Tagen nicht erreichbar. Somit wurden keine Pakete gesendet und dadurch war es auch nicht möglich Zeitangaben zu erhalten. Der einzige Unterschied der bestand, ist, dass sich die IP-Adresse geändert hatte, nämlich von 194.232.104.26 auf 194.232.104.24.
tracert
(Freitag, 25. Jänner 2007, 17:30 Uhr)
tracert
(Samstag, 26. Jänner 2007, 17:32 Uhr)
Wie aus der Definition bereits bekannt ist, so geht es hier um eine Routenverfolgung. Wie man erkennen kann zeigt der Routenverlauf 9 Serverstationen bis dann bei der 10. Serverstation die Seite www.orf.at (= Zielserver) angezeigt wird. Ebenso wie beim Befehl ping, ändert sich auch hier die IP-Adresse von 194.232.104.26 auf 194.232.104.24. Des Weiteren ist ersichtlich, dass am Samstag, den 26. Jänner 2007, die ms (Mikrosekunde) teils größer ist als am Freitag, den 25. Jänner 2007.
2. Portscan
Mit diesem Tool kann festgestellt werden, welche Ports an einem Computer offen sind. D.h., dass dieser Rechner an ein Netzwerk oder an das Internet angeschlossen sein muss um einen Portscan durchführen zu können. Ein solcher Port gilt dann als offen, „wenn Anfragen an diesen Port von der entsprechenden Software bearbeitet werden“.
(Quelle: Vgl. lexexakt.de)
Zur Durchführung eines Portscans auf meinem Rechner, verwendete ich das Online-Portscan Tool von port-scan.de. Hierfür habe ich einen Schnelltest durchgeführt, der mir folgendes Bild als Ergebnis zeigte.
Wie man anhand des Gesamtstatus sehen kann, gilt mein Rechner bzw. meine Ports als sicher. D.h., dass keine der getesteten Ports offen ist bzw. diese durch eine Firewall oder einen Paketfilter überwacht werden.
3. whois-Abfrage
Der Abfragebefehl whois ist englisch und lautet ausgeschrieben „who is“ bzw. „wer ist“. Laut Wikipedia ist whois „ein Protokoll, mit dem von einem verteilten Datenbanksystem Informationen zu Internet-Domains und IP-Adressen und deren Eigentümern abgefragt werden können.
(Quelle: Vgl. Wikipedia)
Im Zusammenhang mit der auszuarbeitenden Aufgabenstellung wurde die whois-Abfrage an der Internetseite des ORF durchgeführt. Folgende Informationen konnten dadurch gewonnen werden:
domain: orf.at
registrant: OR853245-NICAT
admin-c: SL521785-NICAT
tech-c: JJ517250-NICAT
tech-c: ADA567013-NICAT
nserver: ns1.apa.at
remarks: 194.158.133.1
nserver: ns2.apa.at
remarks: 194.158.133.21
changed: 20010509 17:22:26
source: AT-DOM
personname: Stefan Lauterer
organization: Oesterreichischer Rundfunk
street address: Argentinierstrasse 31
postal code: A-1040
city: Wien
country: Austria
phone: +4318787818339
fax-no: +431503621580
e-mail: stefan.lauterer@orf.at
nic-hdl: OR853245-NICAT
changed: 20010509 17:22:24
source: AT-DOM
personname: Stefan Lauterer
organization:
street address: Oesterreichischer Rundfunk
street address: Argentinierstrasse 31
street address: A-1040 Wien
street address: Austria
postal code:
city:
country:
phone: +43 1 87878 18339
fax-no: +43 1 5036215 80
e-mail: stefan.lauterer@orf.at
nic-hdl: SL521785-NICAT
changed: 20001207 11:00:54
source: AT-DOM
personname: Josef Jezek
organization:
street address: ORF Oesterreichischer Rundfunk
street address: Wuerzburggasse 30
street address: A-1136
street address: Austria
postal code:
city:
country:
phone: +43 1 87878 14008
fax-no: +43 1 87878 14949
e-mail: josef.jezek@orf.at
nic-hdl: JJ517250-NICAT
changed: 20000825 13:21:19
source: AT-DOM
personname: APA DNS Admin
organization: APA Austria Presse Agentur
street address: Laimgrubengasse 10
postal code: A-1060
city: Wien
country: Austria
e-mail: domain-admin@apa.at
nic-hdl: ADA567013-NICAT
changed: 20051110 13:29:58
source: AT-DOM
Wie aus der Abfrage ersichtlich ist, so ist die Domain orf.at auf Stefan Lauterer registriert. Darüber hinaus lassen sich Daten ablesen wie Adresse, Telefonnummer etc.
4. Quellen:
Hier sind die im Beitrag verwendeten Quellen nochmals überblicksmäßig dargestellt:
- das ELKO
- lexexakt.de
- Lexikon Suchmaschinenoptimierung
- ORF
- port-scan.de
- Wikipedia: ping
- Wikipedia: whois
Link
(0 Kommentare)
Kommentieren
Donnerstag, 13. Dezember 2007
Donnerstag, 13. Dezember 2007
Spam-Filter
Topic: 'Aufgaben (NiM)'
1. Definition + Funktion:
Unter einem Spam-Filter versteht man ein Computerprogramm bzw. ein Tool (Werkzeug) zum Filtern (Säubern) von Werbung via Internet. Hierbei sei anzumerken, dass diese Werbung auf dem elektronischen Weg erfolgt sowie als unerwünscht empfunden wird (so genannter Spam). (Quelle: Vgl. Wikipedia)
Unter Spam „werden unerwünschte, in der Regel auf elektronischem Weg übertragene Nachrichten bezeichnet, welche dem Empfänger unverlangt zugestellt werden und massenhaft versandt wurden oder werbenden Inhalt haben. Dieser Vorgang wird Spamming oder Spammen genannt, der Verursacher Spammer". (Quelle: Vgl. Wikipedia)
Generell werden Spam-Filter im Zuge von nicht gewünschten E-Mails verwendet bzw. sollen diese durch den Einsatz solcher Programme verhindert werden. Technisch gesehen prüfen Spam-Filter die Nachrichten von E-Mails. Darüber hinaus werden die Adresse des Absenders sowie mögliche Internetadressen kontrolliert. Wird z.B. eine Mail an den Empfänger, welcher diese als störend bzw. unerwünscht empfinden könnte, gesendet, so steigt in diesem Fall der Spam-Filter ein und blockt die Nachricht bzw. das Mail im Vorfeld. (Quelle: Vgl. IT-Lexikon)
2. Arten von Spam-Filter:
Da es viele unterschiedliche Arten von Spams gibt bzw. die Absender von Spam-Mails immer neue Wege entwickeln um einen Empfänger damit zu empfangen unterscheidet man folgende Arten von Spam-Filter:
- Benutzerdefinierte Filter
- Reputationsfilter
- Dateianhang-Filter
- URL-Filter
- Heuristische Filter.
Bei einem benutzerdefinierten Filter, wie der Name schon sagt, kann der Anwender des Programmes selbst wählen, welche Adressen er/sie geblockt haben möchte und welche nicht.
Reputationsfilter sind als Listen zu verstehen, die von bestimmten Institutionen erzeugt und veröffentlicht werden. Daraufhin hat jeder die Möglichkeit diese Listen herunterzuladen und für sein Tool zu verwenden.
Bei Dateianhang-Filter geht es um das Blockieren von E-Mail-Anhängen (wie z.B. Dokumente, Videos, Bilder etc.), welche bestimmte Kriterien aufweisen.
Wie schon bei dem Reputationsfilter beschäftigen sich URL-Filter mit dem Einsatz von Listen. Sobald man die E-Mails abruft erkennt der Mail-Server, ob die jeweilige Adresse eingetragen ist oder nicht und somit blockiert wird bzw. der Empfang gestattet wird.
Laut IT-Lexikon haben Heuristische Filter folgende Aufgabe: „Heuristische Filter analysieren die Struktur der eingegangenen E-Mail. Dabei prüft der Filter Komponenten wie die Betreffzeile oder die Inhalte“. (Quelle: Vgl. IT-Lexikon)
3. Beispiele für Spam-Filter:
Die folgenden Anwendungen stellen nur Beispiele für Spam-Filter Programme bzw. Softwaren dar. In erster Linie sind hier ein paar bekannte und auch kleinere Spam-Filter Anbieter erwähnt. Eine kurze Beschreibung soll Aufschluss geben, was der jeweilige Anbieter mit seiner Anwendung verspricht.
- Barracuda Networks
Stellt eine der größten Spam-Filter Programme weltweit dar. Laut Homepage empfangen sie durchschnittlich 1.000.000.000 Spam- und Virusmeldungen pro Tag (gerechnet von mehr als 50.000 Kunden)
- eleven
Diese stellen deren Produkt als die optimale Lösung für mittlere und große Unternehmen dar. Sie geben weiters an, dass mittels ihrer Software 98% an Spam geblockt bzw. verhindert werden können.
- antispameurope
Dieser Anbieter gibt an 99% aller Spam blocken zu können. Darüber hinaus bieten sie eine Verwaltung für Webmail, POP3, IMAP und DNS an.
- Spamihilator
Diese Software entfernt laut den Herstellern 98% von Spam-Nachrichten. Deren Filter (Bayesian Filter) basiert auf den Regeln von Thomas Bayes (hierbei sei auf den Weblog von Jing Gao verwiesen, welche diese Spam-Filter Technik näher behandelt hat).
- Safermail
geben an, dass durch deren Programm 96% weniger Spam auftreten wird sowie erkennen sie 100% aller Viren (Erhebung: durchschnittliche Scanleistung 01.-08.2006).
Hinsichtlich der Haupthersteller von Spam-Filter weltweit möchte ich ebenfalls auf den Weblog von Jing Gao verweisen, die sehr schön die drei größten, nämlich Ironport, Barracuda Networks und Postini, näher beschrieben hat.
4. Quellen:
Hier sind die im Beitrag verwendeten Quellen nochmals überblicksmäßig dargestellt:
- Wikipedia: Spam-Filter
- Wikipedia: Spam
- IT-Lexikon: Spam-Filter
- Barracuda Networks
- eleven
- antispameurope
- Spamihilator
- Safermail.
Unter einem Spam-Filter versteht man ein Computerprogramm bzw. ein Tool (Werkzeug) zum Filtern (Säubern) von Werbung via Internet. Hierbei sei anzumerken, dass diese Werbung auf dem elektronischen Weg erfolgt sowie als unerwünscht empfunden wird (so genannter Spam). (Quelle: Vgl. Wikipedia)
Unter Spam „werden unerwünschte, in der Regel auf elektronischem Weg übertragene Nachrichten bezeichnet, welche dem Empfänger unverlangt zugestellt werden und massenhaft versandt wurden oder werbenden Inhalt haben. Dieser Vorgang wird Spamming oder Spammen genannt, der Verursacher Spammer". (Quelle: Vgl. Wikipedia)
Generell werden Spam-Filter im Zuge von nicht gewünschten E-Mails verwendet bzw. sollen diese durch den Einsatz solcher Programme verhindert werden. Technisch gesehen prüfen Spam-Filter die Nachrichten von E-Mails. Darüber hinaus werden die Adresse des Absenders sowie mögliche Internetadressen kontrolliert. Wird z.B. eine Mail an den Empfänger, welcher diese als störend bzw. unerwünscht empfinden könnte, gesendet, so steigt in diesem Fall der Spam-Filter ein und blockt die Nachricht bzw. das Mail im Vorfeld. (Quelle: Vgl. IT-Lexikon)
2. Arten von Spam-Filter:
Da es viele unterschiedliche Arten von Spams gibt bzw. die Absender von Spam-Mails immer neue Wege entwickeln um einen Empfänger damit zu empfangen unterscheidet man folgende Arten von Spam-Filter:
- Benutzerdefinierte Filter
- Reputationsfilter
- Dateianhang-Filter
- URL-Filter
- Heuristische Filter.
Bei einem benutzerdefinierten Filter, wie der Name schon sagt, kann der Anwender des Programmes selbst wählen, welche Adressen er/sie geblockt haben möchte und welche nicht.
Reputationsfilter sind als Listen zu verstehen, die von bestimmten Institutionen erzeugt und veröffentlicht werden. Daraufhin hat jeder die Möglichkeit diese Listen herunterzuladen und für sein Tool zu verwenden.
Bei Dateianhang-Filter geht es um das Blockieren von E-Mail-Anhängen (wie z.B. Dokumente, Videos, Bilder etc.), welche bestimmte Kriterien aufweisen.
Wie schon bei dem Reputationsfilter beschäftigen sich URL-Filter mit dem Einsatz von Listen. Sobald man die E-Mails abruft erkennt der Mail-Server, ob die jeweilige Adresse eingetragen ist oder nicht und somit blockiert wird bzw. der Empfang gestattet wird.
Laut IT-Lexikon haben Heuristische Filter folgende Aufgabe: „Heuristische Filter analysieren die Struktur der eingegangenen E-Mail. Dabei prüft der Filter Komponenten wie die Betreffzeile oder die Inhalte“. (Quelle: Vgl. IT-Lexikon)
3. Beispiele für Spam-Filter:
Die folgenden Anwendungen stellen nur Beispiele für Spam-Filter Programme bzw. Softwaren dar. In erster Linie sind hier ein paar bekannte und auch kleinere Spam-Filter Anbieter erwähnt. Eine kurze Beschreibung soll Aufschluss geben, was der jeweilige Anbieter mit seiner Anwendung verspricht.
- Barracuda Networks
Stellt eine der größten Spam-Filter Programme weltweit dar. Laut Homepage empfangen sie durchschnittlich 1.000.000.000 Spam- und Virusmeldungen pro Tag (gerechnet von mehr als 50.000 Kunden)
- eleven
Diese stellen deren Produkt als die optimale Lösung für mittlere und große Unternehmen dar. Sie geben weiters an, dass mittels ihrer Software 98% an Spam geblockt bzw. verhindert werden können.
- antispameurope
Dieser Anbieter gibt an 99% aller Spam blocken zu können. Darüber hinaus bieten sie eine Verwaltung für Webmail, POP3, IMAP und DNS an.
- Spamihilator
Diese Software entfernt laut den Herstellern 98% von Spam-Nachrichten. Deren Filter (Bayesian Filter) basiert auf den Regeln von Thomas Bayes (hierbei sei auf den Weblog von Jing Gao verwiesen, welche diese Spam-Filter Technik näher behandelt hat).
- Safermail
geben an, dass durch deren Programm 96% weniger Spam auftreten wird sowie erkennen sie 100% aller Viren (Erhebung: durchschnittliche Scanleistung 01.-08.2006).
Hinsichtlich der Haupthersteller von Spam-Filter weltweit möchte ich ebenfalls auf den Weblog von Jing Gao verweisen, die sehr schön die drei größten, nämlich Ironport, Barracuda Networks und Postini, näher beschrieben hat.
4. Quellen:
Hier sind die im Beitrag verwendeten Quellen nochmals überblicksmäßig dargestellt:
- Wikipedia: Spam-Filter
- Wikipedia: Spam
- IT-Lexikon: Spam-Filter
- Barracuda Networks
- eleven
- antispameurope
- Spamihilator
- Safermail.
Samstag, 3. November 2007
Samstag, 3. November 2007
Cascading Style Sheets (CSS)
Topic: 'Aufgaben (NiM)'
Erklärung zu CSS:
Laut Wikipedia werden Cascading Style Sheets als „eine deklarative Stylesheet-Sprache für strukturierte Dokumente“ definiert. Eine weitere Definition sieht CSS als „eine Sprache zur Definition von Formeigenschaften einzelner HTML-Dokumente“. Im Zuge dieser Anwendung, trifft man häufig auf den Einsatz in Verbindung mit HTML und XML.
Funktionen:
Die Funktionen, die ein CSS umfasst, sind zahlreich und es sollen daher nur stichwortartig einige aufgelistet werden:
- Schriftgröße, -art und –farbe ändern
- Hyperlinks formatieren
- Rahmen hinzufügen
- Tabellen einfügen
- Hintergrund ändern
- Layout definieren
- Art des Textes ändern (kursiv, fett, etc.)
Entwicklung:
Bereits im Jahr 1995/96 entstand die erste Version von CSS. Generell kann gesagt sein, dass die erstmalige Präsentation dieser „neuen Sprache“ alle Erwartungen bei Weitem übertroffen hat. Das war auch der Anlass dafür, dass das World Wide Web Consortium (W3C) darauf aufmerksam wurde. Im Zuge dessen wurde die anfängliche Variante weiter ausgearbeitet und somit entstanden neue Sprachversionen des Cascading Style Sheets (siehe Wikipedia).
Anwendung (eigene Erfahrung):
Faszinierend bei dem Einsatz von Cascading Style Sheets ist die Möglichkeit, binnen kürzester Zeit, eine HTML-Seite als Vorlage für alle weiteren Seiten zu generieren. D.h., dass man sich z.B. ein gewünschtes Layout für die eigene Homepage erstellen kann, und dieses als eine Art „Standard-Seite“ definiert, um sie für die folgenden HTML-Seiten anzuwenden.
Des Weiteren besteht ein wesentlicher Vorteil darin, dass man zur Ausübung dieser Style Sheets kein geübter EDV-Profi sein muss. Mit schon wenigen Anweisungen kann man z.B. Farben, Schriften oder auch Hintergründe ändern.
Kritik:
Ein Problem, welches ich selbst erfahren musste, ist die Tatsache, dass gewisse Browser (wie z.B. Netscape) die Cascading Style Sheets ganz unterschiedlich darstellen.
Hilfestellungen:
Für jeden der Interesse an CSS gefunden hat, habe ich folglich noch ein paar Links, welche euch mit den Style Sheets eine kleine Unterstützung geben sollen:
- SELFHTML (Stylesheets (CSS))
- bjoernsworld.de (CSS Grundlagen).
Quellen:
- Wikipedia
- SELFHTML
- Dr. Web Magazin Sven Lennartz
- Politnet
- bjoernsworld.de.
Laut Wikipedia werden Cascading Style Sheets als „eine deklarative Stylesheet-Sprache für strukturierte Dokumente“ definiert. Eine weitere Definition sieht CSS als „eine Sprache zur Definition von Formeigenschaften einzelner HTML-Dokumente“. Im Zuge dieser Anwendung, trifft man häufig auf den Einsatz in Verbindung mit HTML und XML.
Funktionen:
Die Funktionen, die ein CSS umfasst, sind zahlreich und es sollen daher nur stichwortartig einige aufgelistet werden:
- Schriftgröße, -art und –farbe ändern
- Hyperlinks formatieren
- Rahmen hinzufügen
- Tabellen einfügen
- Hintergrund ändern
- Layout definieren
- Art des Textes ändern (kursiv, fett, etc.)
Entwicklung:
Bereits im Jahr 1995/96 entstand die erste Version von CSS. Generell kann gesagt sein, dass die erstmalige Präsentation dieser „neuen Sprache“ alle Erwartungen bei Weitem übertroffen hat. Das war auch der Anlass dafür, dass das World Wide Web Consortium (W3C) darauf aufmerksam wurde. Im Zuge dessen wurde die anfängliche Variante weiter ausgearbeitet und somit entstanden neue Sprachversionen des Cascading Style Sheets (siehe Wikipedia).
Anwendung (eigene Erfahrung):
Faszinierend bei dem Einsatz von Cascading Style Sheets ist die Möglichkeit, binnen kürzester Zeit, eine HTML-Seite als Vorlage für alle weiteren Seiten zu generieren. D.h., dass man sich z.B. ein gewünschtes Layout für die eigene Homepage erstellen kann, und dieses als eine Art „Standard-Seite“ definiert, um sie für die folgenden HTML-Seiten anzuwenden.
Des Weiteren besteht ein wesentlicher Vorteil darin, dass man zur Ausübung dieser Style Sheets kein geübter EDV-Profi sein muss. Mit schon wenigen Anweisungen kann man z.B. Farben, Schriften oder auch Hintergründe ändern.
Kritik:
Ein Problem, welches ich selbst erfahren musste, ist die Tatsache, dass gewisse Browser (wie z.B. Netscape) die Cascading Style Sheets ganz unterschiedlich darstellen.
Hilfestellungen:
Für jeden der Interesse an CSS gefunden hat, habe ich folglich noch ein paar Links, welche euch mit den Style Sheets eine kleine Unterstützung geben sollen:
- SELFHTML (Stylesheets (CSS))
- bjoernsworld.de (CSS Grundlagen).
Quellen:
- Wikipedia
- SELFHTML
- Dr. Web Magazin Sven Lennartz
- Politnet
- bjoernsworld.de.