
Mittwoch, 21. Januar 2009
Web 3.0 - Einführung und Überblick
Am Mittwoch, 21. Jan 2009 im Topic 'Aufgaben'
Unter dem Begriff semantic web bzw. Web 3.0 bzw. social semantic web, der von Sir Tim Berners-Lee, dem Erfinder des WWW geprägt wurde, versteht man das Verständlich machen von Daten für Maschinen. Hier rücken also die Maschinen und nicht der Mensch in den zentralen Mittelpunkt, obwohl letztendlich der Mensch daraus Schlüsse und Vorzüge zieht. Sir Tim Berners Lee hat in einem Artikel folgende drei Aussagen zu Entwicklung des Internets erläutert die zum Teil schon erfüllt und zum Teil noch Vision sind vgl. Gruber:
• „Eine kontinuierliche Weiterentwicklung der technischen Infrastruktur in allen Bereichen (Server und Client),
• eine Erleichterung und Intensivierung der menschlichen Kommunikation bzw. eine Verbesserung der Möglichkeiten hierfür und
• die Vision, dass das Web für Maschinen verständlich sein wird“
Die ersten beiden Ausprägungen sind zweifelsohne bereits in die Realität übergegangen, durch präzise Suchmaschinen, schnellere Hardware, leistungssteigernde Software und deren gezielter Fachspezifischer Anwendung. Die dritte Ausprägung, also die Vision der intelligenten Maschinen, steht am Beginn ihres Daseins und ergänzt das vorherrschende aktuell verwendete Internet um eine zusätzliche Schicht, nämlich die Metadateneben, das bedeutet Daten von Daten, oder die formale Beschreibung der Daten. Ähnlich wie bei XML und XLS, oder das später angeführte RFDS für RFD vgl. Gruber.
Web 3.0 die Erweiterung des Web 2.0
Das Web 3.0 baut auf seinen Vorgänger auf und nutzt dessen Technologien und Errungenschaften und ergänzt diese mit spezifischen semantischen Weiterentwicklungen. Ein Ausgangspunkt, wo die beiden Begriffe ineinander übergehen kann im sogenannten Tagging, d.h. in der Beschreibung der Metainformationen für Daten gesehen werden. Grundlegende Idee dahinter ist die Einhaltung von Standards und Konventionen um die dahinterliegenden Ontologien und die Beschreibung der Metadaten zu vereinheitlichen um späteren immensen Zeitaufwand mit der Migration vorzubeugen. Dies stellt im aktuellen Zeitpunkt der Entwicklungen noch eine Problematik dar, da viele Benutzer des Web 2.0 unstrukturiert und Standard verletzend getagged haben. Die nachstehende Abbildung zeigt die Schnittstellen und die Metadatenposition zwischen dem Web 2.0 und semantic web vgl. Stein.
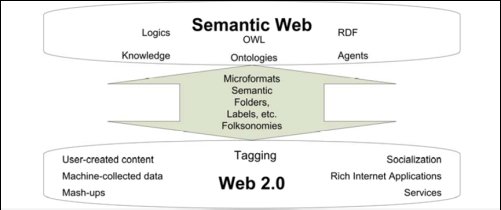
Aktueller Stand der Dinge ist das Tagging der User mit frei wählbaren Begriffen so wird bei vgl. Stein der Begriff „Dame“ gesucht und es werden alle möglichen Ergebnisse die den Tag „Dame“ beinhalten ausgegeben. Dies kann aber nicht auf die eigentliche Semantik hin überprüft werden, da sowohl Bilder von Frauen, der Kirche Notre-Dame in Paris oder Abbildungen von Dame-Spielen angezeigt werden. Eine Gliederung der Tags in die von den Ontologien verwendeten Domänen und Ausprägung wäre sinnvoll um diese Daten die bereits im Netz kursieren zu strukturieren und nachvollziehbar zu machen vgl Stein.
Es werden bereits von einigen Softwaresystemen Funktionalitäten angeboten um diese Vorgehensweise des Strukturierens von Daten für die Benutzer zu vereinfachen und dadurch den Nutzen aller Beteiligten zu steigern. Nachfolgend sind einige Beispiel für diesen strukturierten Aufarbeitungsprozess und Suchmaschinen für den Gebrauch von semantischen Eingaben aufgelistet vgl. Stein:
• http://flickr.com (Die Clusterfunktion der Bilder kann als guter Grundstock gesehen werden)
• http://pipes.yahoo.com (durch Drag&Drop Funktionen können Inhalte aus dem Internet strukturiert und miteinander kombiniert werden)
• http://search.creativecommons.org (Metasuchmaschine die über Google, Yahoo, Flickr, etc. seine freiverfügbaren und relevanten Daten bezieht)
• http://www.freebase.com (Suchinformationen werden mit Metainformationen ergänzt)
Zusammenfassend kann man das Web 3.0 als Ergänzung des Web 2.0 mit semantischen Hintergrundinformationen über Metabeschreibungen der Daten selbst sehen um den Mehrnutzen für alle Beteiligten zu erhöhen und dadurch die Qualität der Informationen verbessern.
Herausforderung des Web 3.0
Die folgenden sechs Punkte setzen sich mit den Herausforderungen mit denen das semantic web konfrontiert ist auseinander und geben zeigen eine Darstellung der Stäken und Chancen dieser Entwicklung auf vgl. Benjamins:
• Verfügbarkeit von Inhalten
• Stabilität der Technologien
• Verringerung der Informationsüberflutung
• Mehrsprachigkeit
• Skalierbarkeit
• Evolution, Entwicklung und Verfügbarkeit von Ontologien
Nähere Informationen bzgl. der einzelnen Punkte können bei Benjamins nachgelesen werden.
Literatur:
Benjamins Richard, Contreras Jesús, Corcho Oscar Gómez-Pérez Asunción, Six Challenges for the Semantic Web, http://www.cs.man.ac.uk/~carole/old/GGF%20Tutorial%20Stuff/Benjaminsetal.pdf, 21.01.2009
Gruber Frank, Semantic Web - Ein Henne Ei-Problem, http://cms.hs-augsburg.de/report/2006/Gruber_Frank__Semantic_Web/Semantic_Web.pdf, 21.01.2009
Stein Armin, Semantic Web vs. Web 2.0, http://www.wi.uni-muenster.de/aw/download/hybride-systeme/Hybrid%2051.pdf, 21.01.2009
• „Eine kontinuierliche Weiterentwicklung der technischen Infrastruktur in allen Bereichen (Server und Client),
• eine Erleichterung und Intensivierung der menschlichen Kommunikation bzw. eine Verbesserung der Möglichkeiten hierfür und
• die Vision, dass das Web für Maschinen verständlich sein wird“
Die ersten beiden Ausprägungen sind zweifelsohne bereits in die Realität übergegangen, durch präzise Suchmaschinen, schnellere Hardware, leistungssteigernde Software und deren gezielter Fachspezifischer Anwendung. Die dritte Ausprägung, also die Vision der intelligenten Maschinen, steht am Beginn ihres Daseins und ergänzt das vorherrschende aktuell verwendete Internet um eine zusätzliche Schicht, nämlich die Metadateneben, das bedeutet Daten von Daten, oder die formale Beschreibung der Daten. Ähnlich wie bei XML und XLS, oder das später angeführte RFDS für RFD vgl. Gruber.
Web 3.0 die Erweiterung des Web 2.0
Das Web 3.0 baut auf seinen Vorgänger auf und nutzt dessen Technologien und Errungenschaften und ergänzt diese mit spezifischen semantischen Weiterentwicklungen. Ein Ausgangspunkt, wo die beiden Begriffe ineinander übergehen kann im sogenannten Tagging, d.h. in der Beschreibung der Metainformationen für Daten gesehen werden. Grundlegende Idee dahinter ist die Einhaltung von Standards und Konventionen um die dahinterliegenden Ontologien und die Beschreibung der Metadaten zu vereinheitlichen um späteren immensen Zeitaufwand mit der Migration vorzubeugen. Dies stellt im aktuellen Zeitpunkt der Entwicklungen noch eine Problematik dar, da viele Benutzer des Web 2.0 unstrukturiert und Standard verletzend getagged haben. Die nachstehende Abbildung zeigt die Schnittstellen und die Metadatenposition zwischen dem Web 2.0 und semantic web vgl. Stein.
Aktueller Stand der Dinge ist das Tagging der User mit frei wählbaren Begriffen so wird bei vgl. Stein der Begriff „Dame“ gesucht und es werden alle möglichen Ergebnisse die den Tag „Dame“ beinhalten ausgegeben. Dies kann aber nicht auf die eigentliche Semantik hin überprüft werden, da sowohl Bilder von Frauen, der Kirche Notre-Dame in Paris oder Abbildungen von Dame-Spielen angezeigt werden. Eine Gliederung der Tags in die von den Ontologien verwendeten Domänen und Ausprägung wäre sinnvoll um diese Daten die bereits im Netz kursieren zu strukturieren und nachvollziehbar zu machen vgl Stein.
Es werden bereits von einigen Softwaresystemen Funktionalitäten angeboten um diese Vorgehensweise des Strukturierens von Daten für die Benutzer zu vereinfachen und dadurch den Nutzen aller Beteiligten zu steigern. Nachfolgend sind einige Beispiel für diesen strukturierten Aufarbeitungsprozess und Suchmaschinen für den Gebrauch von semantischen Eingaben aufgelistet vgl. Stein:
• http://flickr.com (Die Clusterfunktion der Bilder kann als guter Grundstock gesehen werden)
• http://pipes.yahoo.com (durch Drag&Drop Funktionen können Inhalte aus dem Internet strukturiert und miteinander kombiniert werden)
• http://search.creativecommons.org (Metasuchmaschine die über Google, Yahoo, Flickr, etc. seine freiverfügbaren und relevanten Daten bezieht)
• http://www.freebase.com (Suchinformationen werden mit Metainformationen ergänzt)
Zusammenfassend kann man das Web 3.0 als Ergänzung des Web 2.0 mit semantischen Hintergrundinformationen über Metabeschreibungen der Daten selbst sehen um den Mehrnutzen für alle Beteiligten zu erhöhen und dadurch die Qualität der Informationen verbessern.
Herausforderung des Web 3.0
Die folgenden sechs Punkte setzen sich mit den Herausforderungen mit denen das semantic web konfrontiert ist auseinander und geben zeigen eine Darstellung der Stäken und Chancen dieser Entwicklung auf vgl. Benjamins:
• Verfügbarkeit von Inhalten
• Stabilität der Technologien
• Verringerung der Informationsüberflutung
• Mehrsprachigkeit
• Skalierbarkeit
• Evolution, Entwicklung und Verfügbarkeit von Ontologien
Nähere Informationen bzgl. der einzelnen Punkte können bei Benjamins nachgelesen werden.
Literatur:
Benjamins Richard, Contreras Jesús, Corcho Oscar Gómez-Pérez Asunción, Six Challenges for the Semantic Web, http://www.cs.man.ac.uk/~carole/old/GGF%20Tutorial%20Stuff/Benjaminsetal.pdf, 21.01.2009
Gruber Frank, Semantic Web - Ein Henne Ei-Problem, http://cms.hs-augsburg.de/report/2006/Gruber_Frank__Semantic_Web/Semantic_Web.pdf, 21.01.2009
Stein Armin, Semantic Web vs. Web 2.0, http://www.wi.uni-muenster.de/aw/download/hybride-systeme/Hybrid%2051.pdf, 21.01.2009
Permalink (1 Kommentar) Kommentieren
Mittwoch, 26. November 2008
Tools zur Erkundung
Am Mittwoch, 26. Nov 2008 im Topic 'Aufgaben'
In meinem Beitrag werde ich mich der Verfolgung einer Internetseite bzw. dem Überprüfen ob eine Seite verfügbar ist oder nicht widmen.
Zunächst möchte ich auf die Überprüfung mittels CMD-Befehl Ping eingehen:
Ping
Als erstes wird die nachstehende Quelle als guter Überblick über den Ping Befehl angeführt, bei dem die nicht so versierten Personen einen Einblick über den Einsatzbereich bzw. die Anwendung dieses CMD-Befehls geben: Wikipedia Ping (Datenübertragung)
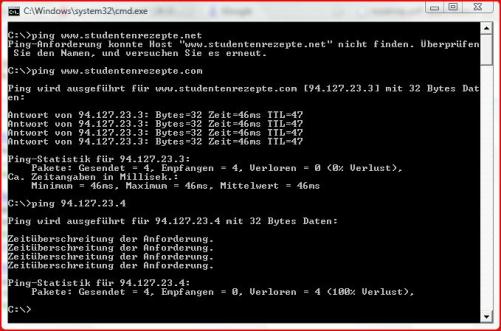
In vorstehender Abbildung werden zwei Versuche gestartet um die Webseite studentenrezepte.com anzusprechen. Dies gelingt beim ersten Versuch auch. Hierbei erhält man die aufgeschlüsselte IP-Adresse der Domain. Es werden 4 Versuche ausgeführt und man erhält im Anschluss eine Statistik über die erfolgreiche bzw. nicht erfolgreiche Überprüfung der Verbindung.
Im Anschluss an diesen Erfolg habe ich die aufgeschlüsselte IP-Adresse verändert um absichtlich einen Fehlaufruf zu starten, der auch prompt vom System abgewehrt wird. Die wird dem Benutzer über die Ausgabe "Zeitüberschreitung ..." signalisiert.
Das Thema Sicherheit ist bei einem Ping-Angriff natürlich ein sehr relevantes, da der Server diese Anfrage bearbeiten muss und bei einer Überbeanspruchung kann es vorkommen, dass der Server aufgibt. Wie in jedem Thema des WWW muss man die Gefahrenquellen kennen, wenn man sich in diese Welt begibt und man sollte sich immer ein Risiko bzw. Problemkonzept bereit halten, im Falle eines Angriffes...
TRACERT
Der zweite Begriff den ich erwähnen möchte ist der Begriff des Trace Route (=Tracert), für die interessierten liefert hier Wikipedia auch einen Bericht: TRACERT.
Bei Traceroute wird der Verbindungsweg der eigenen IP über mögliche Gateways, etc. bis hin zur eingegeben Zieladresse nachverfolgt und es wird einem jede einzelne Verbindung samt Verbindungsstatistik ausgegeben. Nachstehend der Auszug aus dem Traceroute zur Seite orf.at :
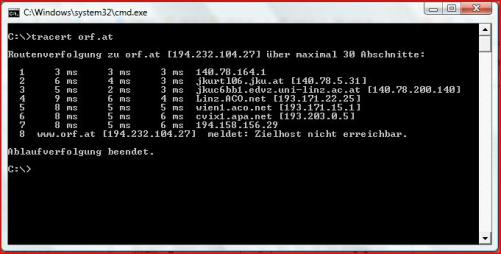
Hierbei sieht man auch die möglichen Probleme die auftreten können. Es könnte die Verbindung abgebrochen werden, was zur prompten Fehlermeldung führt. Man bemerkt eindeutig die Zugehörigkeit der einzelnen IPs mit dereren Verbindungszeiten.
Sicherheit:
zum Thema Sicherheit habe ich folgende Links herausgesucht und gefunden.
- HDM Stuttgart - Sicherheitslücken
- Leitfaden bei Serversperrung
- PC-Welt
Zusätzlich habe ich noch mehrere IP-Ausgabe Tools und Geschwindigkeitstests getestet, nachstehend die Links (einfach ausprobieren, Screenshots machen in meinen Augen keinen Sinn):
- SpeedTest
- IP?
- IPFOO
- etc. etc.
Bei diesen Systemen werden allerdings auch Dinge wie das Betriebssystem, der Browser, etc. ausgelesen was in meinen Augen Sicherheitslücken darstellen und zum gläsernen Menschen beitragt.
Zunächst möchte ich auf die Überprüfung mittels CMD-Befehl Ping eingehen:
Ping
Als erstes wird die nachstehende Quelle als guter Überblick über den Ping Befehl angeführt, bei dem die nicht so versierten Personen einen Einblick über den Einsatzbereich bzw. die Anwendung dieses CMD-Befehls geben: Wikipedia Ping (Datenübertragung)
In vorstehender Abbildung werden zwei Versuche gestartet um die Webseite studentenrezepte.com anzusprechen. Dies gelingt beim ersten Versuch auch. Hierbei erhält man die aufgeschlüsselte IP-Adresse der Domain. Es werden 4 Versuche ausgeführt und man erhält im Anschluss eine Statistik über die erfolgreiche bzw. nicht erfolgreiche Überprüfung der Verbindung.
Im Anschluss an diesen Erfolg habe ich die aufgeschlüsselte IP-Adresse verändert um absichtlich einen Fehlaufruf zu starten, der auch prompt vom System abgewehrt wird. Die wird dem Benutzer über die Ausgabe "Zeitüberschreitung ..." signalisiert.
Das Thema Sicherheit ist bei einem Ping-Angriff natürlich ein sehr relevantes, da der Server diese Anfrage bearbeiten muss und bei einer Überbeanspruchung kann es vorkommen, dass der Server aufgibt. Wie in jedem Thema des WWW muss man die Gefahrenquellen kennen, wenn man sich in diese Welt begibt und man sollte sich immer ein Risiko bzw. Problemkonzept bereit halten, im Falle eines Angriffes...
TRACERT
Der zweite Begriff den ich erwähnen möchte ist der Begriff des Trace Route (=Tracert), für die interessierten liefert hier Wikipedia auch einen Bericht: TRACERT.
Bei Traceroute wird der Verbindungsweg der eigenen IP über mögliche Gateways, etc. bis hin zur eingegeben Zieladresse nachverfolgt und es wird einem jede einzelne Verbindung samt Verbindungsstatistik ausgegeben. Nachstehend der Auszug aus dem Traceroute zur Seite orf.at :
Hierbei sieht man auch die möglichen Probleme die auftreten können. Es könnte die Verbindung abgebrochen werden, was zur prompten Fehlermeldung führt. Man bemerkt eindeutig die Zugehörigkeit der einzelnen IPs mit dereren Verbindungszeiten.
Sicherheit:
zum Thema Sicherheit habe ich folgende Links herausgesucht und gefunden.
- HDM Stuttgart - Sicherheitslücken
- Leitfaden bei Serversperrung
- PC-Welt
Zusätzlich habe ich noch mehrere IP-Ausgabe Tools und Geschwindigkeitstests getestet, nachstehend die Links (einfach ausprobieren, Screenshots machen in meinen Augen keinen Sinn):
- SpeedTest
- IP?
- IPFOO
- etc. etc.
Bei diesen Systemen werden allerdings auch Dinge wie das Betriebssystem, der Browser, etc. ausgelesen was in meinen Augen Sicherheitslücken darstellen und zum gläsernen Menschen beitragt.
Permalink (2 Kommentare) Kommentieren
Freitag, 31. Oktober 2008
Rund um das Web - XML
Am Freitag, 31. Okt 2008 im Topic 'Aufgaben'
Bei dieser Aufgabe habe ich mich für die Auseinandersetzung mit XML entschieden. Meine XML-Datei, DTD bzw. Schema beschäftigen sich mit einem proprieteräen CRM-System.
--> externer Download: DTD
crm xsd (xsd, 5 KB)
xml bsp datei (xml, 12 KB)
Ich habe ebenfalls eine XML Schema Datei erstellt und hochgeladen um die Unterschiede zwischen DTD und XSD zu symbolisieren.
Eine Beschreibung von XSD findet man hier. Woraus auch der Vorteil entsteht, dass man eigene Datentypen definieren kann.
--> externer Download: DTD
crm xsd (xsd, 5 KB)
xml bsp datei (xml, 12 KB)
Ich habe ebenfalls eine XML Schema Datei erstellt und hochgeladen um die Unterschiede zwischen DTD und XSD zu symbolisieren.
Eine Beschreibung von XSD findet man hier. Woraus auch der Vorteil entsteht, dass man eigene Datentypen definieren kann.
Permalink (4 Kommentare) Kommentieren
... ältere Einträge